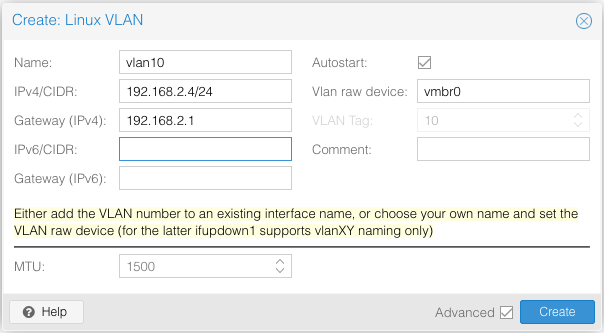
Ich habe seit einigen Jahren in meinem Heimnetz VLANs in Benutzung. Das funktioniert super, aber bisher habe ich mich noch nicht getraut, “Proxmox” auch zur Benutzung von VLANs zu befähigen. Ich habe da mittlerweile mehr als ein Dutzend verschiedene Dienste “produktiv” laufen, und ich wollte einfach nix kaputt machen. 😉
Jetzt am Wochenende war es aber so weit, ich habe mich da ran getraut. Und was soll ich sagen? Meine Sorge, etwas kaputt zu machen, war völlig unbegründet. Das Ganze ist super leicht konfiguriert, und wenn man es gut plant und ein bisschen vorsichtig ist, knirscht es auch nicht im Getriebe… 😉
Da mein (bisher einziger) Proxmox-Node im Headless-Betrieb läuft, besteht die Gefahr mich selbst durch Änderungen an der Netzwerkkonfiguration auszusperren. In einem solchen Fall müsste ich den Mini-PC, auf dem Proxmox läuft, mit einem Monitor und einer Tastatur ausstatten, um diesen wieder bedienen zu können, was — vermeidbaren — Aufwand bedeuten würde.
Ich habe mir daher einen kleinen “Trick” einfallen lassen. Einfach einen USB-Ethernet-Adapter in den Mini-PC eingesteckt, und ich hatte einen zusätzlichen Netzwerkport, über den ich dann als Fallback auf meinen Proxmox-Node zugreifen können würde.
Wer einen Raspberry Pi mit einer Micro-SD betreibt, dem wird wahrscheinlich das Problem nicht fremd sein, dass die Micro-SDs schnell kaputt gehen. Das muss aber nicht sein!
Wenn man ein System hat, dass kaum Dateien auf dem lokalen Dateisystem schreibt oder verändert (abgesehen von Logdateien vielleicht) — in meinem Fall liest der Raspi nur über einen an den USB-Port angeschlossenen Infrarot-Lesekopf einen Stromzähler aus, das Logging erfolgt dabei auf einen Remote-Syslog-Server — dann sollte man das System so konfigurieren, dass das Root-Filesystem als “Overlay”-Filesystem konfiguriert ist.
Änderungen im Filesystem werden dadurch nur in ein “Overlay” im RAM geschrieben, so dass das ursprüngliche Dateisystem auf der Micro-SD nicht verändert wird, was natürlich der Lebensdauer der Micro-SD zugute kommt.
Seit etwa fünf Wochen besitze ich nun meinen ersten “Mini-PC“, einen BMAX B5A Pro, Produktnummer G7R2, nachdem ich bisher immer nur PCs im Standard-Desktop-Format oder im Tower-Gehäuse (Maxi- oder Medi-/Mini-Format) besessen habe, die ich zudem oft selbst gebaut habe. Und ich muss sagen, ich bin begeistert von dem kleinen “Kistchen”.
Warum habe ich mir überhaupt diesen PC gekauft? Ich wollte die Hardware unseres Familien-Intranet-Servers ersetzen, die bisher aus einem alten Dell-Latitude-Laptop bestand. Obwohl dieser ständig nur “idle” läuft, verbraucht er im Durchschnitt etwas mehr als 20 W, was mir einfach zu viel ist. Ein Mini-PC versprach, deutlich weniger Leistung aufzunehmen.
Zum anderen sind meine Ansprüche an die Leistungsfähigkeit eines Intranet-Servers gestiegen, u. a. da ich seit einigen Monaten eine Home Assistant-Instanz auf Docker-Basis betreibe, die zu den bereits bestehenden Anwendungen auf dem Intranet-Server dazu kam. Der Mini-PC verfügt bereits ab Werk über 16 GB RAM (ein Modul mit der Bezeichnung “TDS4CDAG08-32SC22C” des relativ unbekannten Herstellers TWSC, “TechWinSemiConductors”) und eine 500 GB-M.2-SSD (“AirDisk 512GB SSD” des Herstellers “MAXIO Technology (Hangzhou) Ltd.”), was genügend Spielraum für leistungshungrige Anwendungen verspricht. Außerdem ist eine leistungsfähige AMD Ryzen 7 5825U verbaut mit acht Kernen und 16 Threads und einer TDP von lediglich 15(!) Watt.
[According to my own standards, this post about “UEFI booting” was only like 70% “ready” — I had it pending in “draft” state for many months, because I was lacking the time to finish it… I now decided to release it in its current state, simply because I believe it will still be very useful to many people interested in the topic…]
Before we actually dive deep into how UEFI booting works, a short and simple introduction is due.
Introduction
What is UEFI, anyway?
UEFI could be called the successor of the old BIOS concept. It is a unified version and successor of “EFI”, which was an architecture for a platform firmware used to boot operating systems (in the following abbreviated as “OS”), and the corresponding interface to interact with the firmware and the operating system.
The advantages of UEFI over the traditional BIOS are, among others, the following:
Boot disks with large partitions (over 2 TB), using GUID partitioning (GPT),
network capabilities already in pre-OS phase, and
modular design.
Boot Mechanism
So, how does booting with UEFI work?
When you enter your UEFI, you will find a user interface that shows all devices that have been detected, and that support booting. Usually that includes all your hard drives.
You can freely define a desired boot order (regardless of hardware paths, i.e. the way your drives are connected, be it via an SATA port, be it via an NVME slot), i. e. the primary OS that should be booted, if that fails the next OS that should be tried, etc. That’s called your “boot configuration”, and it resides in your motherboard’s NVRAM. (a concept that’s basically the successor of what used to be called “CMOS” in the old days of the BIOS). More specifically, we speak about “UEFI Variables“, which allow the OS and the firmware to interact.
When UEFI’s Firmware Boot Manager wants to boot an OS, it first needs to load something called the OS “Boot Manager.” Common OS boot managers are:
BOOTMGFW.EFI used to load Windows, or
SHIMX64.EFI used to load Linux
The OS boot manager is located on the “EFI system partition” (ESP). This is a small partition (usually only a few 100 M) at the start of your hard drive, formatted with basically a FAT filesystem. FAT is a very simple filesystem, so that the code to parse it and load files from it can be reasonably small and fit into a boot firmware.
A typical disk layout for a Windows installation may look as follows:
UEFI /EFI System Partition as seen under Windows
The first partition is the ESP, then comes the Windows boot and system drive (with a drive letter of C:), and then comes the recovery partition.
Apart from boot loaders, the ESP can contain kernel images or (device) drivers, e. g. to support hardware that must be initialized prior to the start of the OS, or to give access to a complex filesystem that holds the actual OS to be booted.
Depending on which OS you want to boot, the OS boot manager then loads
in the case of Linux: the OS kernel, and the kernel in turn loads the OS, or
in the case of Windows: the Windows Boot Loader (\Windows\system32\winload.efi)
Boot Configuration Details
Now that we got a good overview of the mechanism as a whole, let’s dive into the details. Let’s look at the boot configuration of my machine. To do so, invoke the below command (I did it under Ubuntu 23.04, but it should work the same under any reasonably current Linux distro where the tool is installed):
So, what does the above tell us? First, we see that “(Boot)0003” is the boot entry used to start the currently running system. Secondly, the order in which boot is tried is 0000, 0002, and then 0003. So by default, Windows (by the “Windows Boot Manager”) will be booted. Then we see the three boot entries. The star/asterisk (*) after the boot entry shows that all these entries are “active.”
What about the remaining info in the above command output? Immediately after the boot entry, we see the names that are also displayed on screen by the Firmware Boot Manager (“Windows Boot Manager” and two times “ubuntu”). We then see references to the ESPs used to boot these OS.
HD obviously means “hard drive”, then we see a 1 which refers to the first partition on the respective drive, then we see GPT which refers to the partitioning table format, and then we see a UUID. To find the respective partitions, we can use the below command:
The PARTUUID values in the above output match the UUIDs in the boot configuration as shown by efibootmgr. So, the ESPs are located by searching for the partitions’ UUIDs. That means that you can replug your drives to different ports, or even copy partitions to different drives, and the UEFI boot mechanism will still find them. That’s a nice and very stable design.
UEFI User Interface
Now, let’s enter the UEFI and look at some of the details there. My PC’s motherboard is an MSI, and to enter the UEFI I need to press “F2” after the beep when powering on the PC (from “off” state, not when suspended to RAM, i.e. “sleeping”!) or restarting it.
Each of the three cmdline scanners caused an error, as shown above.
It seems there was a change in Exim from upstream, as reported by another user. Somehow it seems that if you define a cmdline scanner that uses a chain of commands, when there was an error return code encountered in the middle of the chain, the whole chain is considered failed.
To “fix” this issue (or rather work-around it), I changed the three ACL clauses as follows:
To make sure I didn’t break the malware scanning by my changes, I downloaded the EICAR test virus and sent it to myself. Exim caught the “virus” and ditched it.
I didn’t want to rely upon services like DynDNS.org (which obviously was a smart decision since they now pretty much closed their free service) so I rolled my own…
What you need is the following:
Host your domain yourself using the popular nameserver “Bind.”
Host a small CGI script that will tell you your external IP (or use one of the many free services available that do the same).
Run a machine within your LAN 24×7 which can detect changes of your external IP and update your hostname accordingly.
Step 1: Setup Bind for Dynamic DNS Update
to do
Step 2: CGI Script
The CGI script that needs to be deployed somewhere in the Internet to tell you your external IP is very simple and tiny and looks like this:
Here’s the script that needs to run periodically on a machine (I use Ubuntu server) within your LAN (or on your Internet gateway, although if you have the means to run stuff on your gateway you could employ a more elegant, “proper” solution):
#!/bin/bash
lockfile="/run/extip"
lockfile-check $lockfile
if [ $? -eq 0 ]; then
echo "Locked, bailing out..."
exit 1
fi
lockfile-create $lockfile
filename="/var/lib/extip.txt"
logfile="/var/log/extip.log"
keyfile="/root/var/lib/dyndns/Kmyhost.dyn.example.org.+163+56719.key"
cur_ip=`curl -s http://example.org/cgi-bin/myip.sh`
prev_ip=`cat $filename`
if [ $cur_ip != $prev_ip ]; then
echo "`date --rfc-3339=seconds` IP changed, old IP: $prev_ip, new IP: $cur_ip" >>$logfile
echo "$cur_ip" >$filename
# Wait 5 sec to complete, force kill if nsupdate not done after 10 sec
timeout -k 10s 5s nsupdate -k $keyfile -v<<EOF
server example.org
zone dyn.example.org.
update delete myhost.dyn.example.org. A
update add myhost.dyn.example.org. 60 A $cur_ip
send
EOF
fi
lockfile-remove $lockfile
The above script — even though it’s pretty small — is not a quick’n’dirty hack, but even employs some sanity checks:
It makes sure that only one instance is running at any time, and
it uses the timeout command from the Linux coreutils package to enforce that the nsupdate command will be terminated if it takes longer than 10 s (e. g. due to network issues).
I upgraded from Debian 6.0 (Squeeze) to Debian 7.0 (Wheezy) today. In general the upgrade was relatively painless, but as always some things went worse than they could… 🙁
My local Subversion repository is using a Berkeley DB, and the underlying BDB version went up from 4.8 to 5.1. In consequence I got an error when I wanted to check in a changed config file:
svn: DB_VERSION_MISMATCH: Database environment version mismatch
svn: bdb: Program version 5.1 doesn't match environment version 4.8
I remember that this has already been an issue with the last major Debian upgrade… Did I miss something in the release notes or package doc, or did the Debian folks miss this one?!
Anyway, here’s how to repair the above (based on instructions found here). Install packages db4.8-util and db5.1-util and execute the following commands:
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.