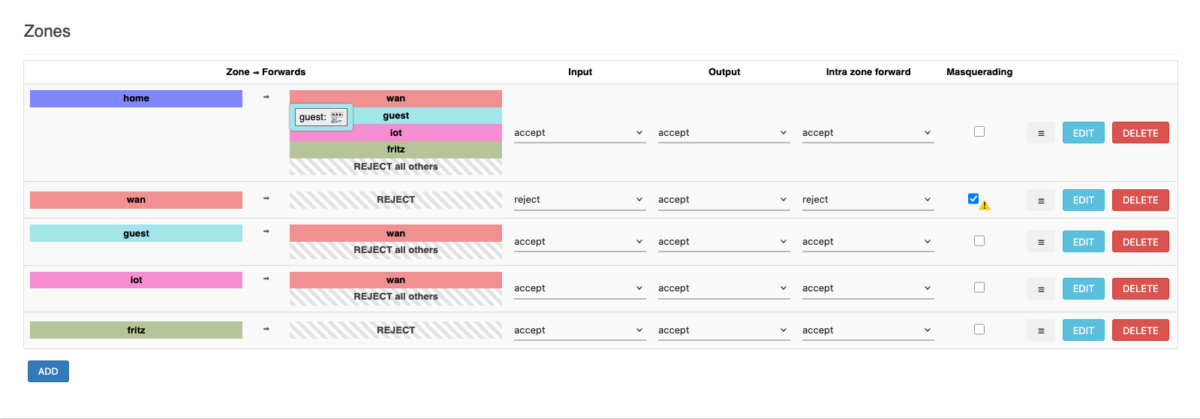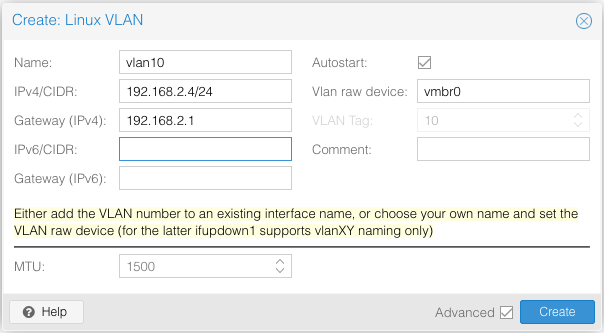
Ich habe seit einigen Jahren in meinem Heimnetz VLANs in Benutzung. Das funktioniert super, aber bisher habe ich mich noch nicht getraut, “Proxmox” auch zur Benutzung von VLANs zu befähigen. Ich habe da mittlerweile mehr als ein Dutzend verschiedene Dienste “produktiv” laufen, und ich wollte einfach nix kaputt machen. 😉
Jetzt am Wochenende war es aber so weit, ich habe mich da ran getraut. Und was soll ich sagen? Meine Sorge, etwas kaputt zu machen, war völlig unbegründet. Das Ganze ist super leicht konfiguriert, und wenn man es gut plant und ein bisschen vorsichtig ist, knirscht es auch nicht im Getriebe… 😉
Da mein (bisher einziger) Proxmox-Node im Headless-Betrieb läuft, besteht die Gefahr mich selbst durch Änderungen an der Netzwerkkonfiguration auszusperren. In einem solchen Fall müsste ich den Mini-PC, auf dem Proxmox läuft, mit einem Monitor und einer Tastatur ausstatten, um diesen wieder bedienen zu können, was — vermeidbaren — Aufwand bedeuten würde.
Ich habe mir daher einen kleinen “Trick” einfallen lassen. Einfach einen USB-Ethernet-Adapter in den Mini-PC eingesteckt, und ich hatte einen zusätzlichen Netzwerkport, über den ich dann als Fallback auf meinen Proxmox-Node zugreifen können würde.